
Código ensamblador y memoria.
Empecemos repasando qué es el código ensamblador. Es bien sabido que los programadores escriben software utilizando lenguajes de programación. Estos lenguajes pueden verse como algoritmos que describen las instrucciones que se necesitan realizar para hacer cierta tarea. Un ejemplo de código en el lenguaje C es:
int sum3mul2(int n) {
int x = n + 3;
int y = x * 2;
return y;
}
El código anterior es una función que devuelve un entero (indicado por el int en su firma) llamada “sum3mul2”, y como su nombre sugiere, recibe un número (“int n”) al que suma 3 y multiplica dos. El valor resultante es y, que devuelve (con “return”) al terminar.
Los lenguajes de programación están diseñados para ser fácilmente comprendidos por humanos. Ofrecen abstracciones para facilitar esto: tipos, variables, funciones, etc. Pero esto no es algo que un procesador pueda entender. Para crear código que pueda ser interpretado por el hardware (código máquina), se debe pasar por un proceso de compilación. Desde el código fuente en lenguaje C a la ejecución del programa, ocurren varios pasos.
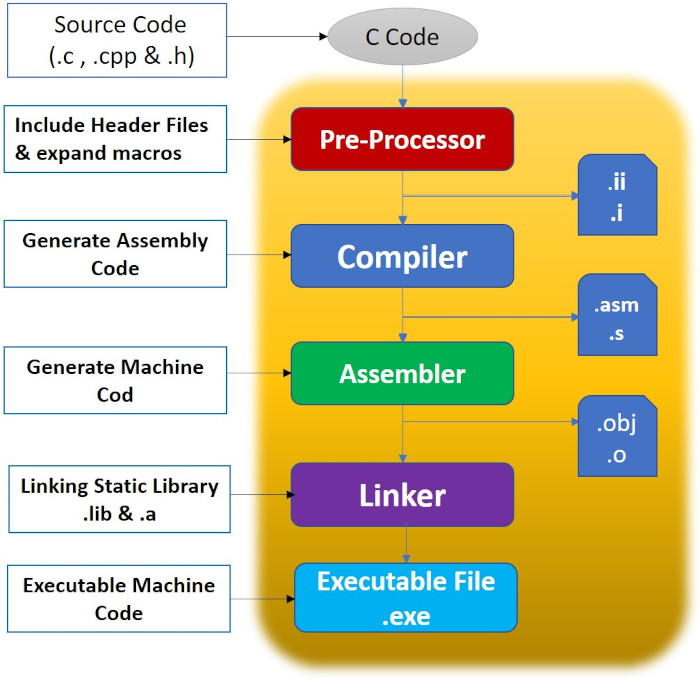
Primero, el programa C pasa por el preprocesador. Este toma todas las directivas de preprocesamiento (#include, #define, #ifdef, etc.) y produce un programa en lenguaje C, con todo esto procesado. Después, se pasa por la fase de compilación. El compilador es el que se encarga de traducir las estructuras y sentencias del lenguaje de programación al lenguaje enesamblador del conjunto de instrucciones de la arquitectura objetivo (en nuestro caso, una arquitectura ARM). Esto aún no puede ser interpretado por la computadora, ya que esta última solo comprende datos en binario, pero ya es una traducción uno a uno de las instrucciones que interpretará el procesador. Una instrucción en ensamblador se compone de un mnemónico que indica cuál es la instrucción, y los operandos de esta. Finalmente, antes de ejecutar el programa, se pasa por un proceso de enlazado para unir al binario ejecutable con sus dependencias y cargarlo a memoria.
La función sum3mul12 vista anteriormente en lenguaje C, al traducirse a lenguaje ensamblador, puede verse algo así:
ldr r2,[n]
add r2,3
str r2,[x]
ldr r3,[x]
mul r3,2
str r3,[y]
ret
Debajo de las abstracciones del lenguaje C, nos encontramos con los que realmente manejan los procesadores: instrucciones, registros, operandos y direcciones de memoria.
En su forma más esencial, una computadora no es más que un procesador y memoria. La memoria es un conjunto de celdas, organizadas por direcciones, que almacenan una unidad de datos (por lo general un byte, u 8 bits). El procesador es una unidad que puede manipular datos para hacer operaciones lógicas-aritméticas, con datos que guarda en sus registros. Los registros son pequeñas unidades de almacenamiento contenidas en el procesador. El procesador puede ejecutar instrucciones para acceder a la memoria, ya sea para tomar datos de una dirección y almacenarla en un registro (LOAD), o pasarla de un registro a una dirección de memoria (STORE).
El código máquina que se obtiene de ensamblar el código es de 32 bits por instrucción, en la arquitectura ARM (en Modo ARM, más adelante veremos que existe el modo Thumb que reduce esto a la mitad). Por ejemplo, el código de MOV r2, 3 sería:
En hexadecimal:
"0xe3a02003"
o en binario:
"0b11100011101000000010000000000011"
Este es el código que termina interpretandose por el procesador.
Tipos de datos
Volvamos a lo básico para ver cuáles instrucciones puede realizar la arquitectura ARM32 y con qué tipo de datos.
Al ser una arquitectura de 32 bits, significa que el tamaño de la palabra, es decir, de sus registros, es 32, a lo que se le llama Word. Existe también el tipo Halfword (de 16 bits) y el Byte (de 8 bits).
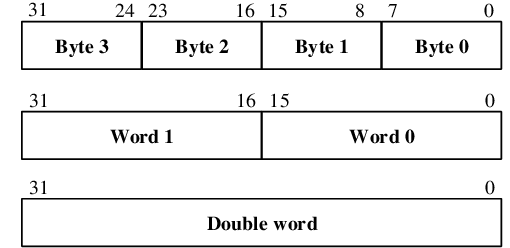
Como se ha mencionado antes, ARM es una arquitectura de tipo LOAD-STORE, es decir, que para pasar algo de memoria a registro o de registro a memoria se utilizan las instrucciones LOAD y STORE, respectivamente. Estas instrucciones tienen variaciones de acuerdo al tipo de dato que quieras cargar (Word, Halfword, o Byte), y estas dos últimas a su vez tienen dos variaciones entre con signo y sin signo.
| Tamaño de palabra | LOAD sin signo | LOAD con signo | STORE sin signo | STORE con signo |
|---|---|---|---|---|
| Word | LDR | STR | ||
| Halfword | LDRH | LDRSH | STRH | STRSH |
| Byte | LDRB | LDRSB | STRB | STRSB |
El utilizar una u otra instrucción puede tener consecuencias en el rendimiento, pues algunas instrucciones pueden consumir más ciclos de reloj. El motivo por la que existe esta distinción es histórico [1], pero puede resumirse en que antes no existían instrucciones tipo LOAD para halfwords o bytes, por lo que en nuevas iteraciones de la arquitectura se introdujeron por separado.
Endianness
Para palabras de tamaño mayor a un byte es necesario definir cómo se guardará en memoria cada uno de sus bytes. De esto se trata el concepto de Endianness. Esto se puede resumir a lo siguiente:
-
Big-Endian: La primera dirección de memoria contiene el byte más significativo y la última contiene el byte menos significativo.
-
Little-Endian: La primera dirección de memoria contiene el byte menos significativo y la última contiene el byte más significativo.
Ejemplo: Supóngase que tenemos la palabra de 32 bits 0x12345678. Está compuesta de cuatro bytes: 0x12, 0x34, 0x56, 0x78, donde 0x12 es el byte más significativo y 0x78 es el byte menos significativo. Supongamos que queremos acomodarlo en las direcciones de memoria de la 1000 a la 1003.
| Direccion | 1000 | 1001 | 1002 | 1003 |
|---|---|---|---|---|
| Big-Endian | 0x12 |
0x34 |
0x56 |
0x78 |
| Little-Endian | 0x78 |
0x56 |
0x34 |
0x12 |
Registros
La arquitectura ARM32 cuenta con 30 registros de propósito general y específico (con la excepción de los Cortex-M), donde los primeros 16 se utilizan en espacio de usuario y los demás están reservados para ejecución de software privilegiado. A continuación se muestran los registros utilizados en espacio de usuario, su alias, y su propósito.
| Registro | Alias | Propósito |
|---|---|---|
| R0 | General | |
| R1 | General | |
| R2 | General | |
| R3 | General | |
| R4 | General | |
| R5 | General | |
| R6 | General | |
| R7 | Guarda el número de llamada al sistema | |
| R8 | General | |
| R9 | General | |
| R10 | General | |
| R11 | FP | Apuntador al frame |
| R12 | IP | Llamada intraprocedural |
| R13 | SP | Apuntador al Stack |
| R14 | LR | Registro de elnace |
| R15 | PC | Contador del programa |
| CPSR | Registro de Estatus Actual del Programa |
Los registros del 0 al 12 pueden ser utilizados como registros de propósito general para cargar datos o direcciones de memoria. El registro 7 sirve cuando se realizan llamadas al sistema, pues este guarda el identificador de la llamada al sistema que se realizará. El registro 11 es el apuntador al frame, lo que nos ayuda a mantener un control sobre las variables locales y parámetros de la función que se está ejecutando actualmente (más adelante veremos más sobre Stack Frames).
El registro 13, similar al Stack Pointer, apunta a una parte del stack. Este nos sirve para mantener un control de las variables en la función actual y para guardar datos de forma temporal.
El registro 14 nos sirve para guardar la dirección de retorno de una función, es decir, la dirección a la que va a regresar la ejecución una vez que termine de ejecutarse la subfunción.
El registro 15, nos sirve para llevar un control del flujo de ejecución del programa. PC apunta a la siguiente dirección que va a ejecutarse. Sin embargo, hay un truco en ARM: debido al pipeline de ARM, el dato que contiene PC siempre está dos instrucciones adelante de la que se está ejecutando actualmente. (8 bytes en modo ARM y 4 bytes en modo Thumb), no una instrucción adelante como se esperaría. Esto significa que si en una instrucción operas el registro PC, de forma efectiva será como si hubieras operado la dirección de la instrucción siguiente a la siguiente.
Banderas (Registro CPSR)
El registro CPSR muestra el estatus de las banderas del procesador. Cada bandera, compuesta por uno o más bits del CPSR, indican información sobre el estado actual de la ejecución o sobre la última instrucción que modificó dicha bandera.

A continuación se muestra el significado de las banderas pertinentes al curso:
-
N (Negativo): Se habilita si el resultado de una instrucción es un número negativo.
-
Z (Cero): Se habilita si el resultado de una instrucción es cero.
-
C (Carry): Se habilita si el resultado de una instrucción requiere del bit 33 para ser representado completamente. También es llamado Overflow sin signo.
-
V (oVerflow): Similar a Carry, pero para operaciones con signo. En complemento a 2, el bit 32 se utiliza como signo negativo, por lo que si la parte numérica del número con signo requiere más de 31 bits para ser representado, se activa esta bandera.
-
E (Endian): Indica la Endianness actual. Recordemos que ARM es una arquitectura Bi-Endian y ser tanto Big Endian (E=1) o Little Endian (E=0).
-
T (Thumb): Se habilita cuando el procesador está en modo Thumb y se deshabilita cuando está en modo ARM.
-
M (Modo): Estos bits especifican el nivel de privilegio de ejecución actual.
-
J (Jazelle): Algunos procesadores ARM permiten la ejecución de bytecode de Java en hardware, indicado por este tercer modo de ejecución.
Hemos visto las partes principales que componen a un procesador de la arquitectura ARM32. En la siguiente parte de esta serie, veremos más a detalle el conjunto de instrucciones de dicha arquitectura.
[1] Thomas, D. 3 de marzo del 2012. Efficient C for ARM: Memory Access. Recuperado de: http://www.davespace.co.uk/arm/efficient-c-for-arm/memaccess.html